library(stochtree)Posterior Summary and Visualization Utilities
This vignette demonstrates the summary and plotting utilities available for stochtree models.
Setup
Load necessary packages
import numpy as np
import matplotlib.pyplot as plt
from stochtree import BARTModel, BCFModel, plot_parameter_traceSet a seed for reproducibility
random_seed = 1234
set.seed(random_seed)random_seed = 1234
rng = np.random.default_rng(random_seed)Supervised Learning
We begin with the supervised learning use case served by the bart() function.
Below we simulate a simple regression dataset.
n <- 1000
p_x <- 10
p_w <- 1
X <- matrix(runif(n * p_x), ncol = p_x)
W <- matrix(runif(n * p_w), ncol = p_w)
f_XW <- (((0 <= X[, 10]) & (0.25 > X[, 10])) *
(-7.5 * W[, 1]) +
((0.25 <= X[, 10]) & (0.5 > X[, 10])) * (-2.5 * W[, 1]) +
((0.5 <= X[, 10]) & (0.75 > X[, 10])) * (2.5 * W[, 1]) +
((0.75 <= X[, 10]) & (1 > X[, 10])) * (7.5 * W[, 1]))
noise_sd <- 1
y <- f_XW + rnorm(n, 0, 1) * noise_sdn = 1000
p_x = 10
p_w = 1
X = rng.uniform(size=(n, p_x))
W = rng.uniform(size=(n, p_w))
# R uses X[,10] (1-indexed) = Python X[:,9]
f_XW = (
((X[:, 9] >= 0) & (X[:, 9] < 0.25)) * (-7.5 * W[:, 0]) +
((X[:, 9] >= 0.25) & (X[:, 9] < 0.5)) * (-2.5 * W[:, 0]) +
((X[:, 9] >= 0.5) & (X[:, 9] < 0.75)) * ( 2.5 * W[:, 0]) +
((X[:, 9] >= 0.75) & (X[:, 9] < 1.0)) * ( 7.5 * W[:, 0])
)
noise_sd = 1.0
y = f_XW + rng.standard_normal(n) * noise_sdNow we fit a simple BART model to the data.
num_gfr <- 10
num_burnin <- 0
num_mcmc <- 1000
general_params <- list(
num_threads = 1,
num_chains = 3
)
bart_model <- stochtree::bart(
X_train = X,
y_train = y,
leaf_basis_train = W,
num_gfr = num_gfr,
num_burnin = num_burnin,
num_mcmc = num_mcmc,
general_params = general_params
)bart_model = BARTModel()
bart_model.sample(
X_train=X,
y_train=y,
leaf_basis_train=W,
num_gfr=10,
num_burnin=0,
num_mcmc=1000,
general_params={
"num_threads": 1,
"num_chains": 3
},
)We obtain a high level summary of the BART model by running print().
print(bart_model)stochtree::bart() run with mean forest, global error variance model, and mean forest leaf scale model
Continuous outcome was modeled as Gaussian with a leaf regression prior with 1 bases for the mean forest
Outcome was standardized
The sampler was run for 10 GFR iterations, with 3 chains of 0 burn-in iterations and 1000 MCMC iterations, retaining every iteration (i.e. no thinning) print(bart_model)BARTModel run with mean forest, global error variance model, and mean forest leaf scale model
Outcome was modeled as gaussian with a leaf regression prior with 1 bases for the mean forest
Outcome was standardized
The sampler was run for 10 GFR iterations, with 3 chains of 0 burn-in iterations and 1000 MCMC iterations, retaining every iteration (i.e. no thinning)For a more detailed summary (including the information above), we use the summary() function.
summary(bart_model)stochtree::bart() run with mean forest, global error variance model, and mean forest leaf scale model
Continuous outcome was modeled as Gaussian with a leaf regression prior with 1 bases for the mean forest
Outcome was standardized
The sampler was run for 10 GFR iterations, with 3 chains of 0 burn-in iterations and 1000 MCMC iterations, retaining every iteration (i.e. no thinning)
Summary of sigma^2 posterior:
3000 samples, mean = 0.895, standard deviation = 0.047, quantiles:
2.5% 10% 25% 50% 75% 90% 97.5%
0.8084663 0.8354853 0.8619096 0.8927078 0.9272022 0.9552168 0.9908970
Summary of leaf scale posterior:
3000 samples, mean = 0.007, standard deviation = 0.001, quantiles:
2.5% 10% 25% 50% 75% 90%
0.005022884 0.005492911 0.005980975 0.006564506 0.007374873 0.008304079
97.5%
0.009749566
Summary of in-sample posterior mean predictions:
1000 observations, mean = -0.063, standard deviation = 3.284, quantiles:
2.5% 10% 25% 50% 75% 90% 97.5%
-6.8439105 -4.9413282 -1.8213713 -0.1199945 2.0077018 4.2607277 6.4900123 print(bart_model.summary())BART Model Summary:
-------------------
BARTModel run with mean forest, global error variance model, and mean forest leaf scale model
Outcome was modeled as gaussian with a leaf regression prior with 1 bases for the mean forest
Outcome was standardized
The sampler was run for 10 GFR iterations, with 3 chains of 0 burn-in iterations and 1000 MCMC iterations, retaining every iteration (i.e. no thinning)
Summary of sigma^2 posterior: 3000 samples, mean = 0.938, standard deviation = 0.049, quantiles:
2.5%: 0.847
10.0%: 0.877
25.0%: 0.905
50.0%: 0.937
75.0%: 0.970
90.0%: 1.002
97.5%: 1.038
Summary of leaf scale posterior: 3000 samples, mean = 0.007, standard deviation = 0.001, quantiles:
2.5%: 0.005
10.0%: 0.005
25.0%: 0.006
50.0%: 0.007
75.0%: 0.008
90.0%: 0.008
97.5%: 0.009
Summary of in-sample posterior mean predictions:
1000 observations, mean = 0.106, standard deviation = 3.286, quantiles:
2.5%: -6.741
10.0%: -4.345
25.0%: -1.943
50.0%: 0.169
75.0%: 2.113
90.0%: 4.431
97.5%: 6.589
NoneWe can use the plot() function to produce a traceplot of model terms like the global error scale \(\sigma^2\) or (if \(\sigma^2\) is not sampled) the first observation of cached train set predictions.
plot(bart_model)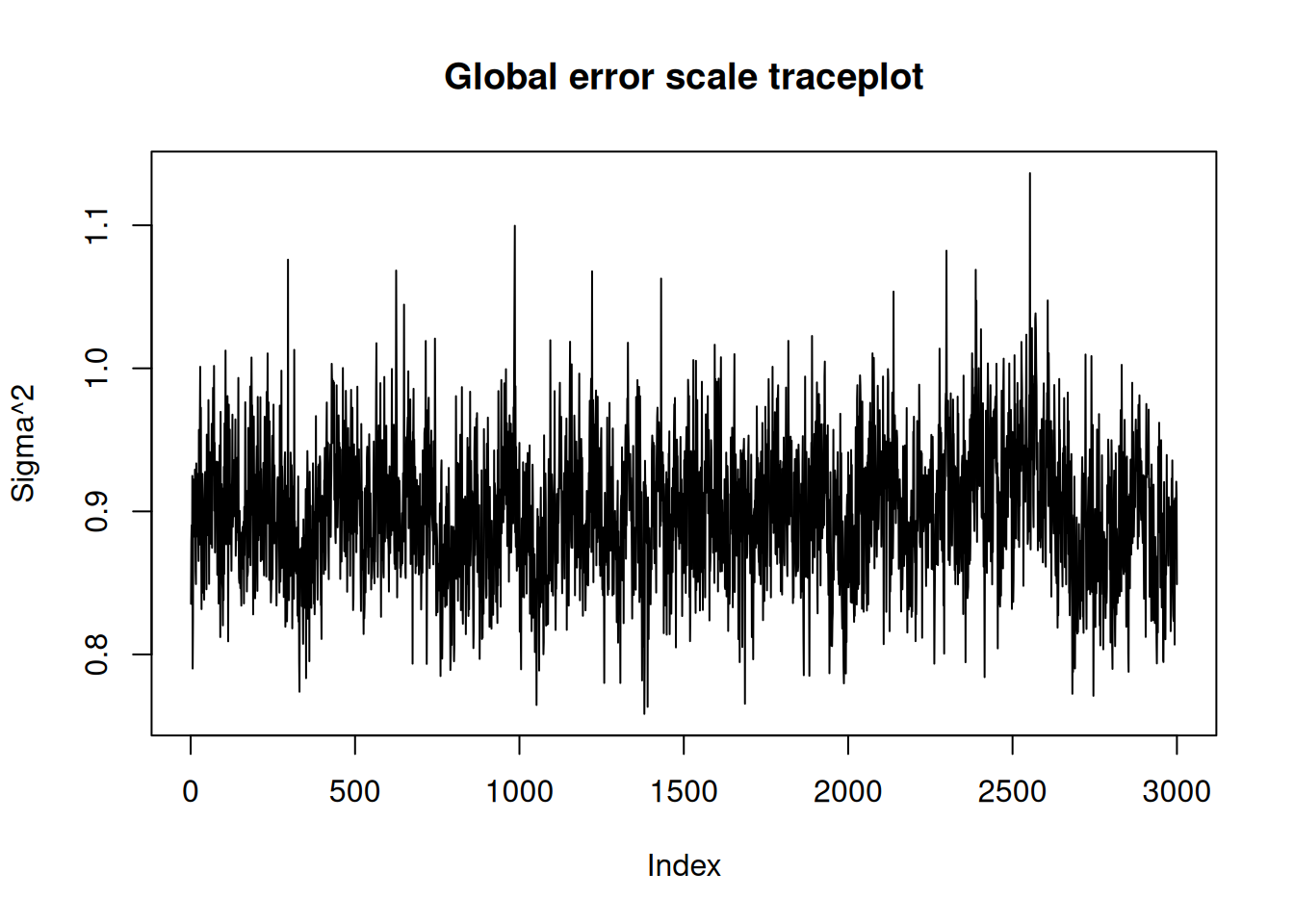
ax = plot_parameter_trace(bart_model, term="global_error_scale")
plt.show()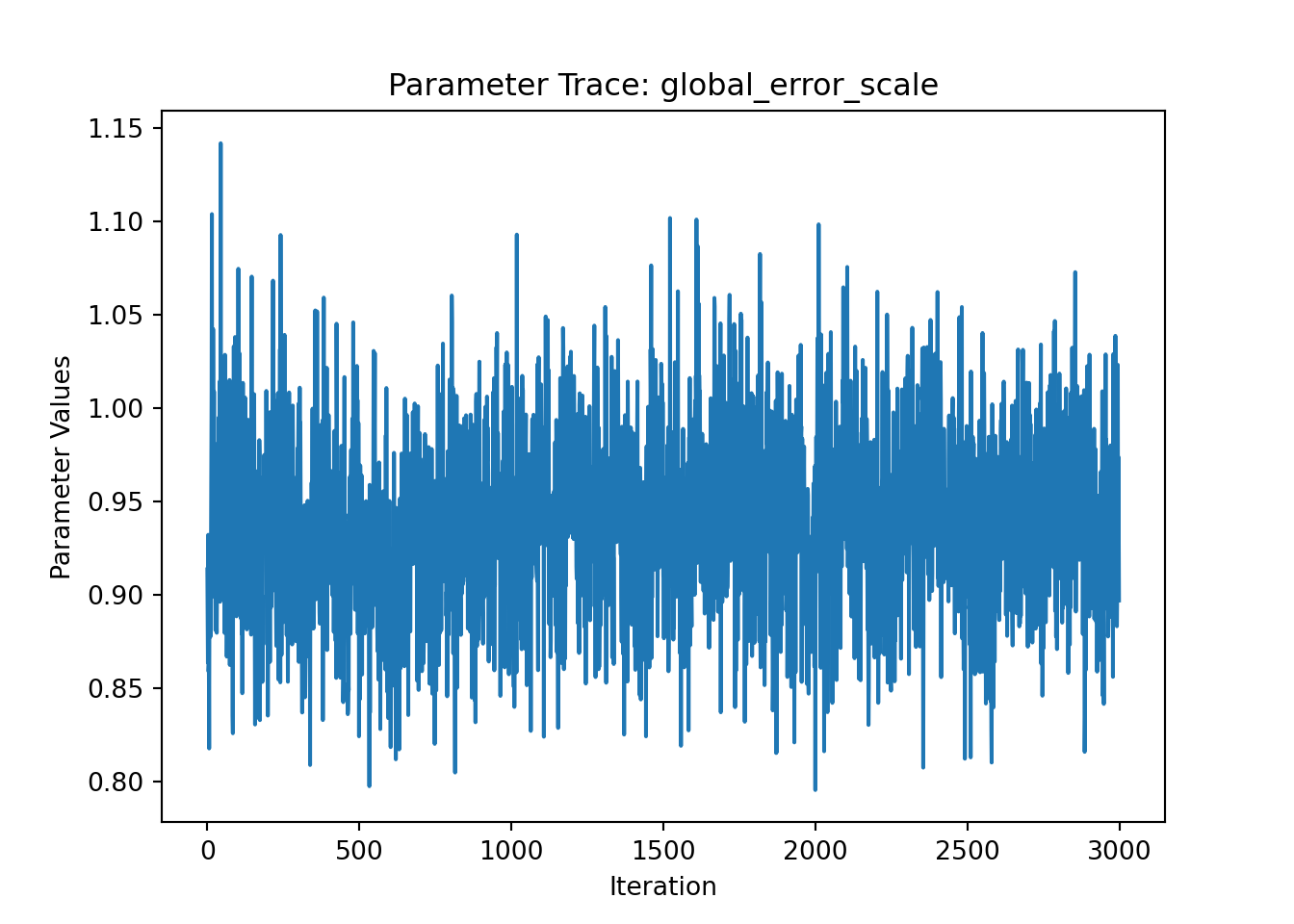
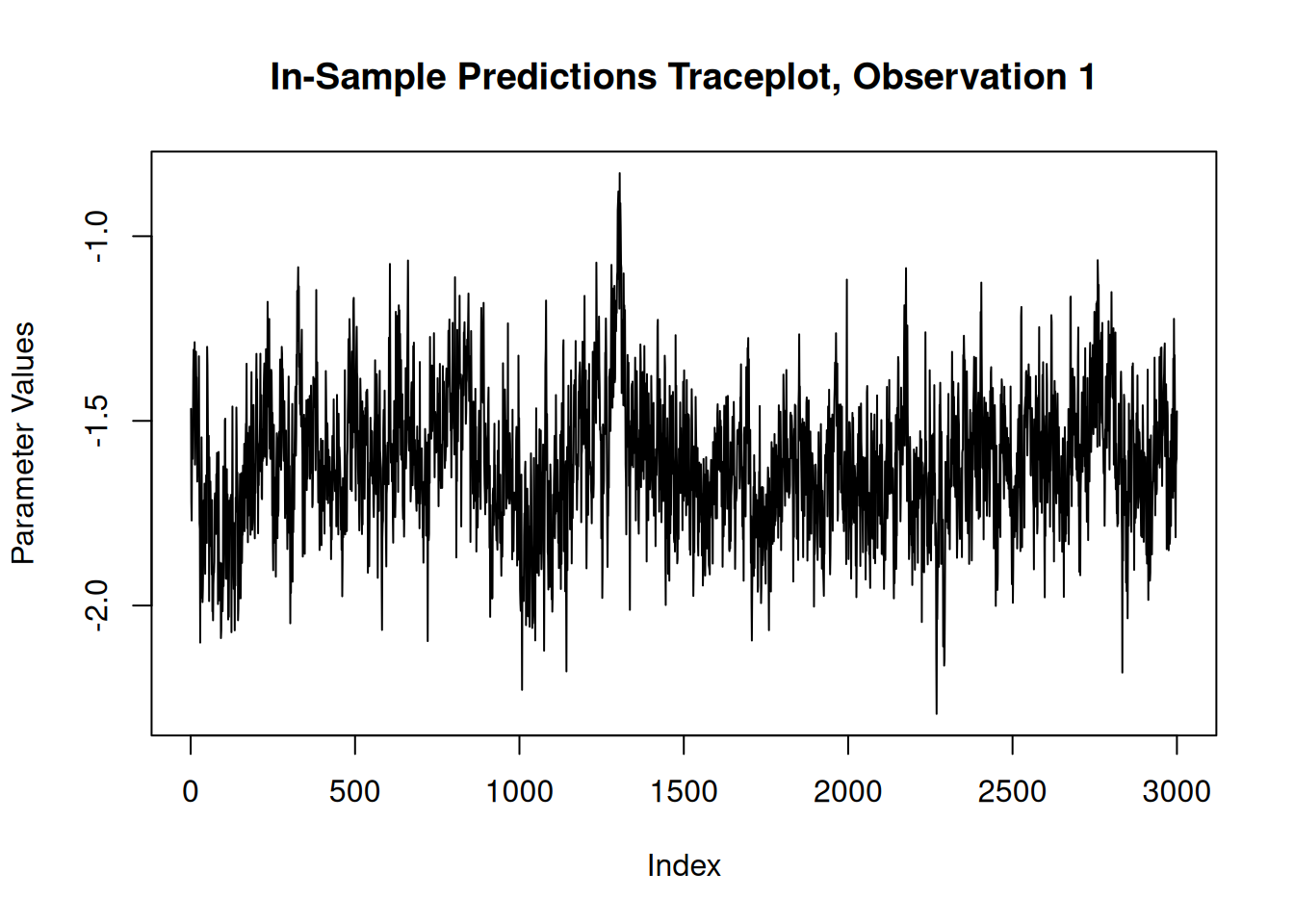
For finer-grained control over which parameters to plot, we can also use the extractParameter() function to pull the posterior distribution of any valid model term (e.g., global error scale \(\sigma^2\), leaf scale \(\sigma^2_{\ell}\), in-sample mean function predictions y_hat_train) and then plot any subset or transformation of these values.
y_hat_train_samples <- extractParameter(bart_model, "y_hat_train")
obs_index <- 1
plot(
y_hat_train_samples[obs_index, ],
type = "l",
main = paste0("In-Sample Predictions Traceplot, Observation ", obs_index),
xlab = "Index",
ylab = "Parameter Values"
)
y_hat_train_samples = bart_model.extract_parameter("y_hat_train")
obs_index = 0
fig, ax = plt.subplots()
ax.plot(y_hat_train_samples[obs_index, :])
ax.set_title(f"In-Sample Predictions Traceplot, Observation {obs_index}")
ax.set_xlabel("Index")
ax.set_ylabel("Parameter Values")
plt.show()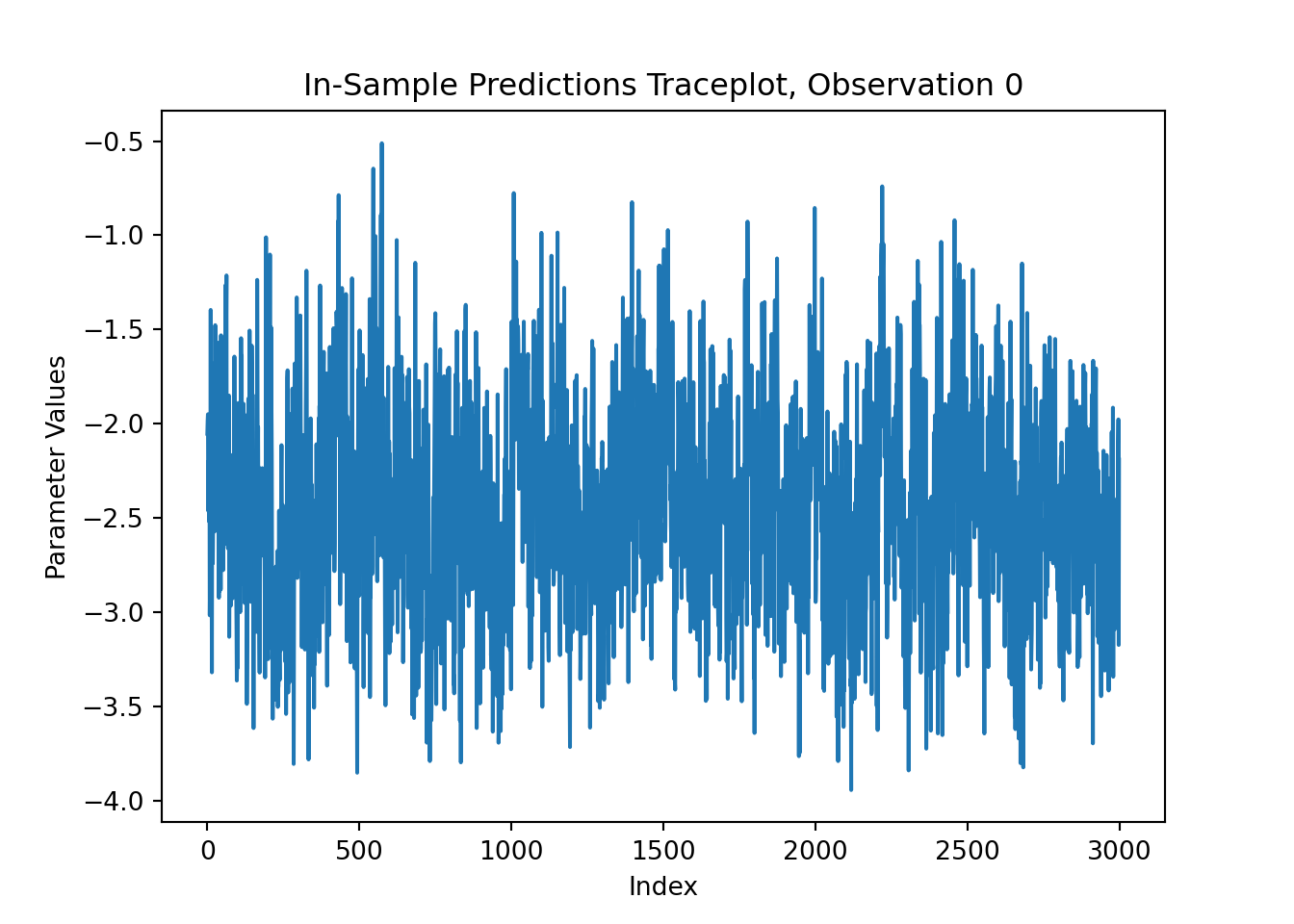
Causal Inference
We now run the same demo for the causal inference use case served by the bcf() function in R and the BCFModel Python class.
Below we simulate a simple dataset for a causal inference problem with binary treatment and continuous outcome.
# Generate covariates and treatment
n <- 1000
p_X = 5
X = matrix(runif(n * p_X), ncol = p_X)
pi_X = 0.25 + 0.5 * X[, 1]
Z = rbinom(n, 1, pi_X)
# Define the outcome mean functions (prognostic and treatment effects)
mu_X = pi_X * 5 + 2 * X[, 3]
tau_X = X[, 2] * 2 - 1
# Generate outcome
epsilon = rnorm(n, 0, 1)
y = mu_X + tau_X * Z + epsilon# Generate covariates and treatment
n = 1000
p_X = 5
X = rng.uniform(size=(n, p_X))
pi_X = 0.25 + 0.5 * X[:, 0]
Z = rng.binomial(1, pi_X, n).astype(float)
# Define the outcome mean functions (prognostic and treatment effects)
mu_X = pi_X * 5 + 2 * X[:, 2]
tau_X = X[:, 1] * 2 - 1
# Generate outcome
epsilon = rng.standard_normal(n)
y = mu_X + tau_X * Z + epsilonNow we fit a simple BCF model to the data
num_gfr <- 10
num_burnin <- 0
num_mcmc <- 1000
general_params <- list(
num_threads = 1,
num_chains = 3,
adaptive_coding = TRUE
)
bcf_model <- stochtree::bcf(
X_train = X,
y_train = y,
Z_train = Z,
num_gfr = num_gfr,
num_burnin = num_burnin,
num_mcmc = num_mcmc,
general_params = general_params
)bcf_model = BCFModel()
bcf_model.sample(
X_train=X,
Z_train=Z,
y_train=y,
propensity_train=pi_X,
num_gfr=10,
num_burnin=0,
num_mcmc=1000,
general_params={
"num_threads": 1,
"num_chains": 3,
"adaptive_coding": True
},
)We obtain a high level summary of the BCF model by running print().
print(bcf_model)stochtree::bcf() run with prognostic forest, treatment effect forest, global error variance model, prognostic forest leaf scale model, and treatment effect intercept model
Outcome was modeled as gaussian
Treatment was binary and its effect was estimated with adaptive coding
outcome was standardized
An internal propensity model was fit using stochtree::bart() in lieu of user-provided propensity scores
The sampler was run for 10 GFR iterations, with 3 chains of 0 burn-in iterations and 1000 MCMC iterations, retaining every iteration (i.e. no thinning) print(bcf_model)BCFModel run with prognostic forest, treatment effect forest, global error variance model, prognostic forest leaf scale model, and treatment effect intercept model
Outcome was modeled as gaussian
Treatment was binary and its effect was estimated with adaptive coding
Outcome was standardized
User-provided propensity scores were included in the model
The sampler was run for 10 GFR iterations, with 3 chains of 0 burn-in iterations and 1000 MCMC iterations, retaining every iteration (i.e. no thinning)For a more detailed summary (including the information above), we use the summary() function / method.
summary(bcf_model)stochtree::bcf() run with prognostic forest, treatment effect forest, global error variance model, prognostic forest leaf scale model, and treatment effect intercept model
Outcome was modeled as gaussian
Treatment was binary and its effect was estimated with adaptive coding
outcome was standardized
An internal propensity model was fit using stochtree::bart() in lieu of user-provided propensity scores
The sampler was run for 10 GFR iterations, with 3 chains of 0 burn-in iterations and 1000 MCMC iterations, retaining every iteration (i.e. no thinning)
Summary of sigma^2 posterior:
3000 samples, mean = 0.948, standard deviation = 0.046, quantiles:
2.5% 10% 25% 50% 75% 90% 97.5%
0.8612806 0.8911718 0.9157341 0.9462258 0.9779726 1.0074856 1.0385681
Summary of prognostic forest leaf scale posterior:
3000 samples, mean = 0.002, standard deviation = 0.000, quantiles:
2.5% 10% 25% 50% 75% 90%
0.000908978 0.001080862 0.001262013 0.001498533 0.001784155 0.002043084
97.5%
0.002475996
Summary of adaptive coding parameters:
3000 samples, mean (control) = -0.454, mean (treated) = 1.002, standard deviation (control) = 0.349, standard deviation (treated) = 0.354
quantiles (control):
2.5% 10% 25% 50% 75% 90%
-1.19410739 -0.90348454 -0.68372289 -0.44269060 -0.21349489 -0.02423392
97.5%
0.21857728
quantiles (treated):
2.5% 10% 25% 50% 75% 90% 97.5%
0.3798293 0.5736983 0.7543187 0.9740120 1.2132759 1.4570656 1.8109981
Summary of treatment effect intercept (tau_0) posterior:
3000 samples, mean = 0.136, standard deviation = 0.782, quantiles:
2.5% 10% 25% 50% 75% 90% 97.5%
-1.3717617 -1.0891631 -0.3088470 0.1693315 0.7446541 1.0738739 1.5073765
Summary of in-sample posterior mean predictions:
1000 observations, mean = 3.487, standard deviation = 0.945, quantiles:
2.5% 10% 25% 50% 75% 90% 97.5%
1.666454 2.278896 2.818287 3.483078 4.138062 4.746473 5.434899
Summary of in-sample posterior mean CATEs:
1000 observations, mean = 0.064, standard deviation = 0.520, quantiles:
2.5% 10% 25% 50% 75% 90% 97.5%
-0.7253229 -0.5625624 -0.3996405 -0.0266764 0.5708963 0.7679216 0.8995149 print(bcf_model.summary())BCF Model Summary:
------------------
BCFModel run with prognostic forest, treatment effect forest, global error variance model, prognostic forest leaf scale model, and treatment effect intercept model
Outcome was modeled as gaussian
Treatment was binary and its effect was estimated with adaptive coding
Outcome was standardized
User-provided propensity scores were included in the model
The sampler was run for 10 GFR iterations, with 3 chains of 0 burn-in iterations and 1000 MCMC iterations, retaining every iteration (i.e. no thinning)
Summary of sigma^2 posterior: 3000 samples, mean = 0.873, standard deviation = 0.042, quantiles:
2.5%: 0.795
10.0%: 0.820
25.0%: 0.844
50.0%: 0.870
75.0%: 0.899
90.0%: 0.928
97.5%: 0.959
Summary of prognostic forest leaf scale posterior: 3000 samples, mean = 0.002, standard deviation = 0.001, quantiles:
2.5%: 0.001
10.0%: 0.001
25.0%: 0.001
50.0%: 0.002
75.0%: 0.002
90.0%: 0.003
97.5%: 0.003
Summary of adaptive coding parameters:
3000 samples, mean (control) = -0.508, mean (treated) = 1.139, standard deviation (control) = 0.337, standard deviation (treated) = 0.328
quantiles (control):
2.5%: -1.226
10.0%: -0.970
25.0%: -0.723
50.0%: -0.477
75.0%: -0.269
90.0%: -0.096
97.5%: 0.067
quantiles (treated):
2.5%: 0.560
10.0%: 0.724
25.0%: 0.914
50.0%: 1.133
75.0%: 1.346
90.0%: 1.558
97.5%: 1.846
Summary of treatment effect intercept (tau_0) posterior: 3000 samples, mean = -0.369, standard deviation = 0.558, quantiles:
2.5%: -1.458
10.0%: -1.140
25.0%: -0.811
50.0%: -0.312
75.0%: 0.077
90.0%: 0.308
97.5%: 0.631
Summary of in-sample posterior mean predictions:
1000 observations, mean = 3.482, standard deviation = 0.962, quantiles:
2.5%: 1.849
10.0%: 2.200
25.0%: 2.781
50.0%: 3.476
75.0%: 4.166
90.0%: 4.760
97.5%: 5.331
Summary of in-sample posterior mean CATEs:
1000 observations, mean = -0.030, standard deviation = 0.623, quantiles:
2.5%: -1.078
10.0%: -0.920
25.0%: -0.578
50.0%: 0.048
75.0%: 0.539
90.0%: 0.737
97.5%: 0.915
NoneIn R, we have a plot() that produces a traceplot of model terms like the global error scale \(\sigma^2\) or (if \(\sigma^2\) is not sampled) the first observation of cached train set predictions.
In Python, we provide a plot_parameter_trace() function for requesting a traceplot of a specific model parameter.
plot(bcf_model)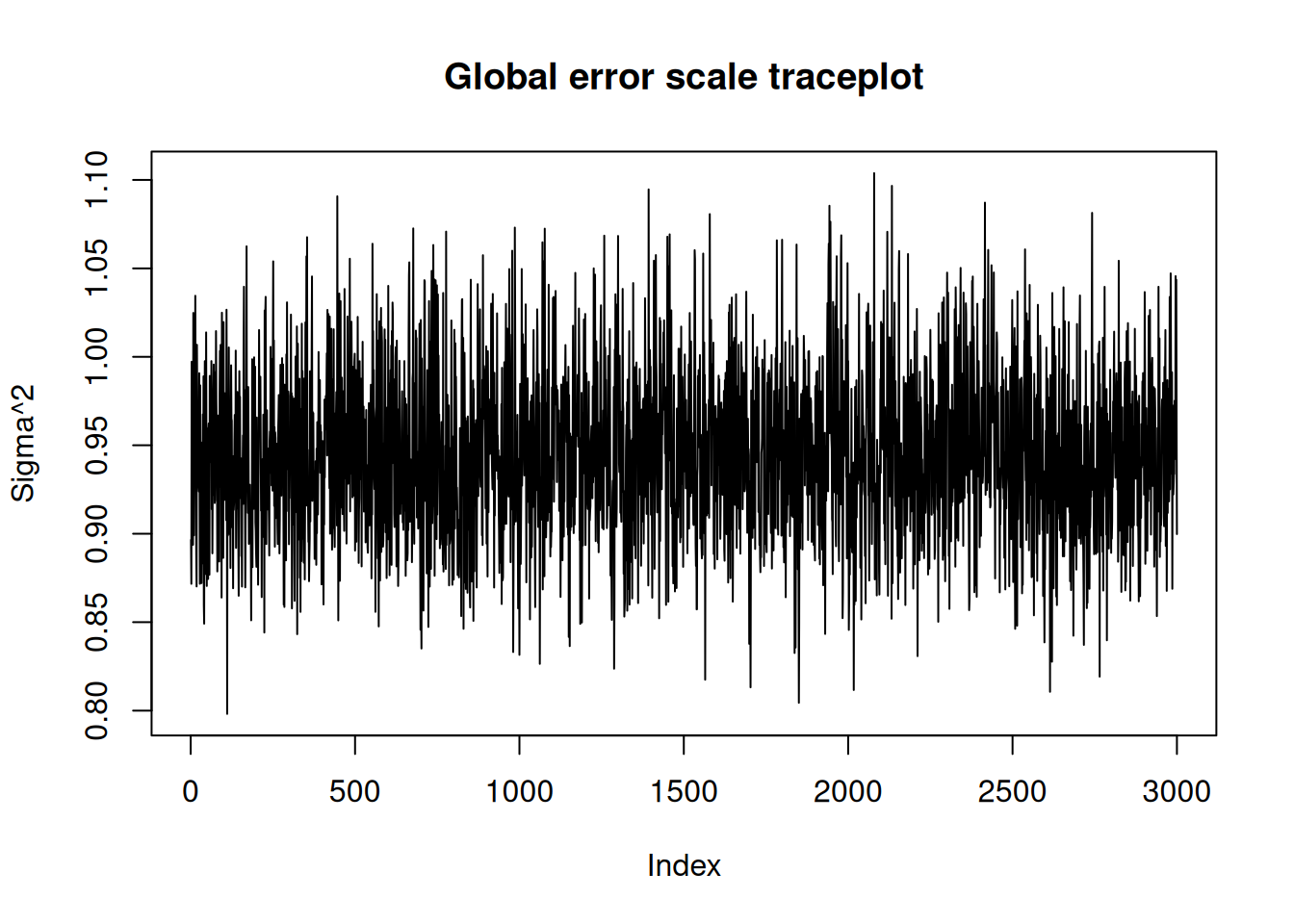
ax = plot_parameter_trace(bcf_model, term="global_error_scale")
plt.show()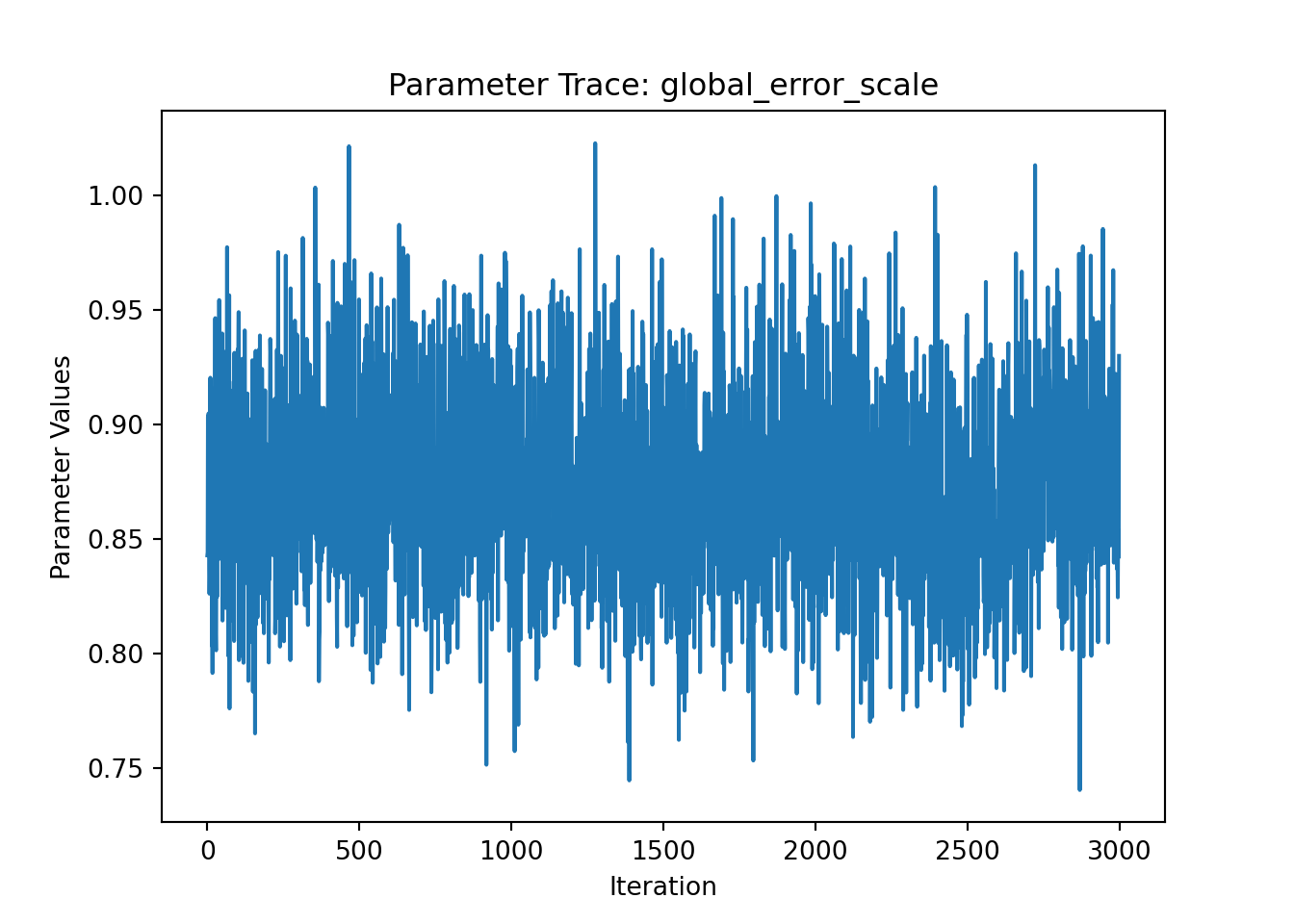
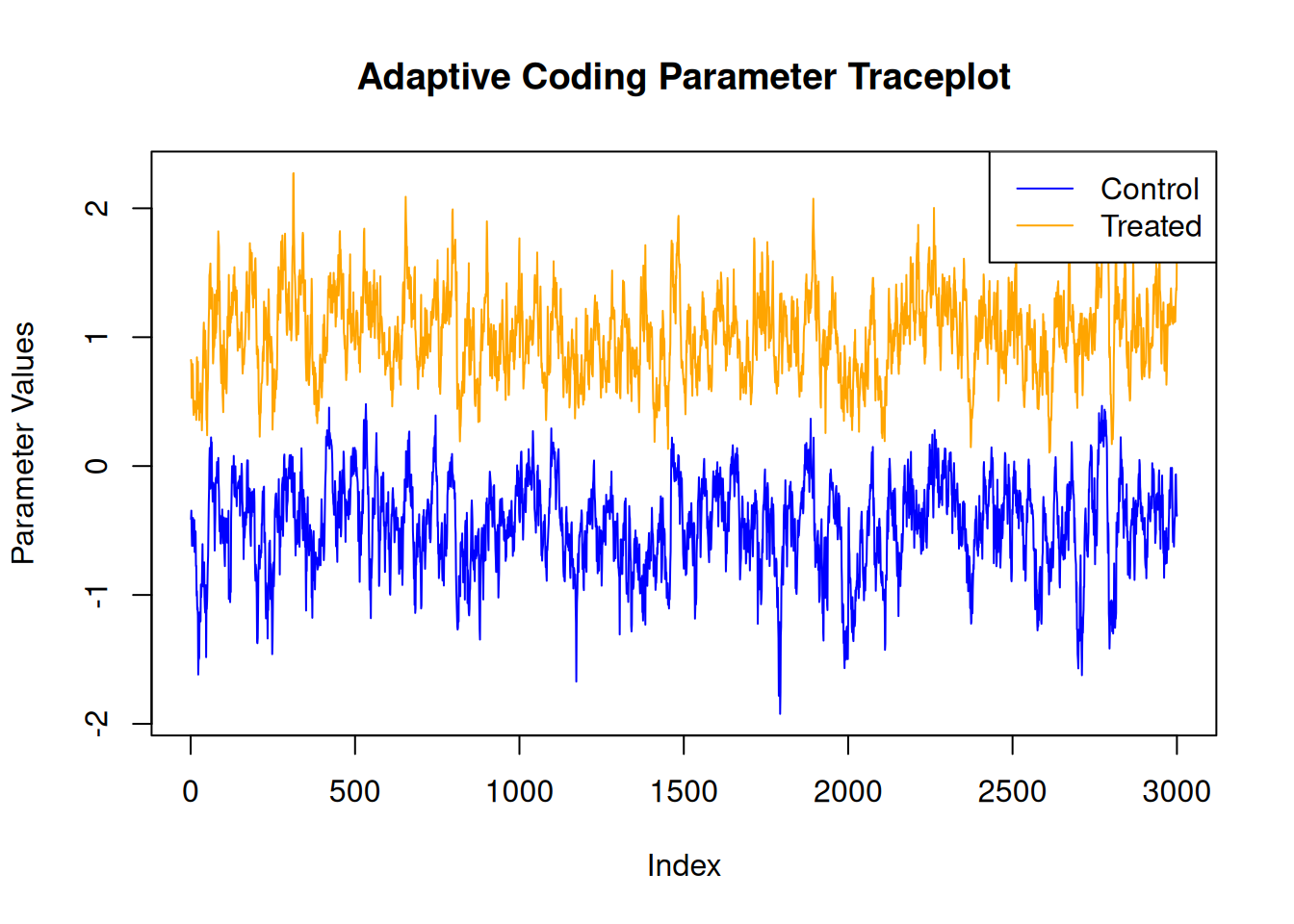
For finer-grained control over which parameters to plot, we can also use the extractParameter() function in R or the extract_parameter() method in Python to query the posterior distribution of any valid model term (e.g., global error scale \(\sigma^2\), prognostic forest leaf scale \(\sigma^2_{\mu}\), CATE forest leaf scale \(\sigma^2_{\tau}\), adaptive coding parameters \(b_0\) and \(b_1\) for binary treatment, in-sample mean function predictions y_hat_train, in-sample CATE function predictions tau_hat_train) and then plot any subset or transformation of these values.
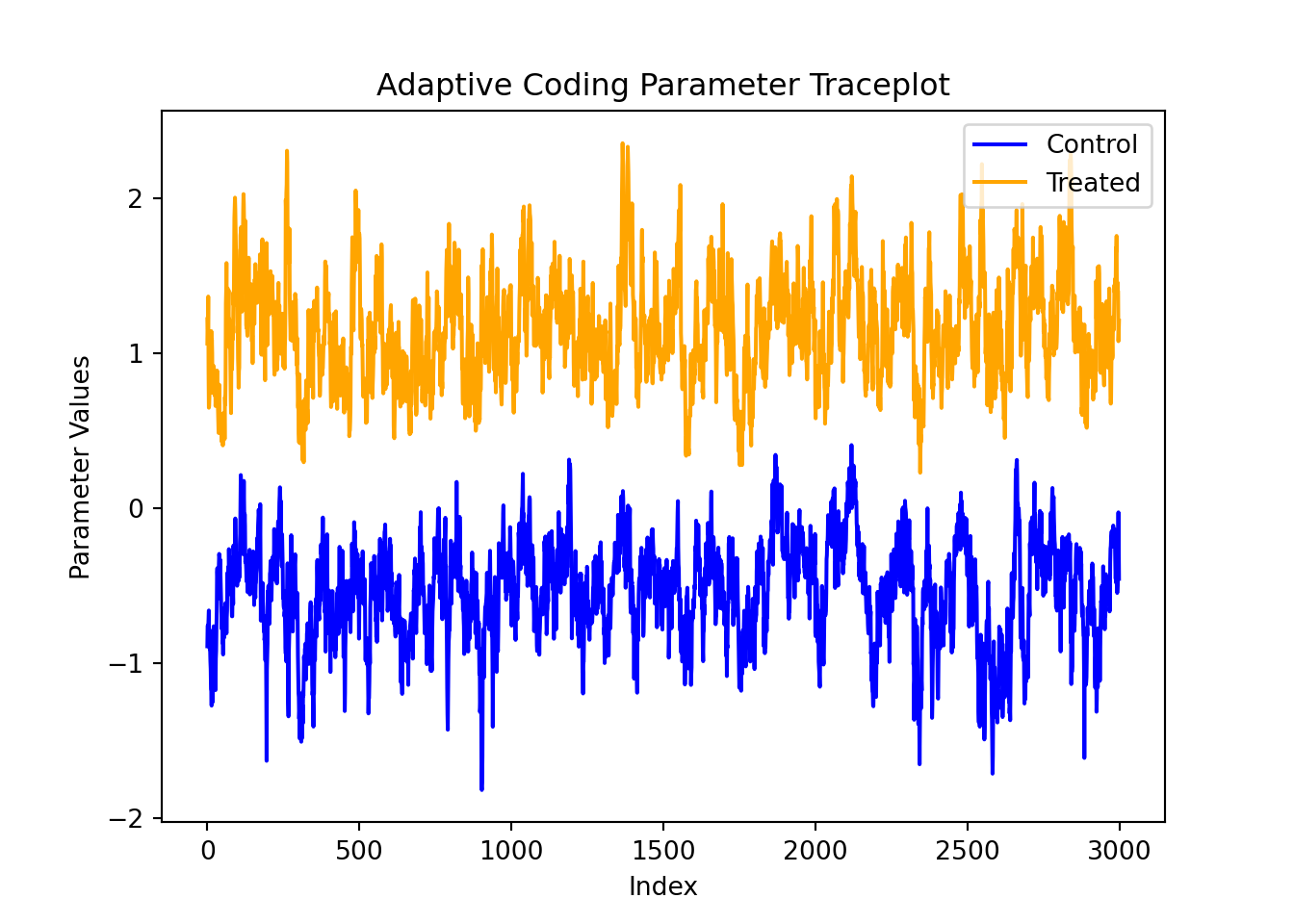
adaptive_coding_samples <- extractParameter(bcf_model, "adaptive_coding")
plot(
adaptive_coding_samples[1, ],
type = "l",
main = "Adaptive Coding Parameter Traceplot",
xlab = "Index",
ylab = "Parameter Values",
ylim = range(adaptive_coding_samples),
col = "blue"
)
lines(adaptive_coding_samples[2, ], col = "orange")
legend(
"topright",
legend = c("Control", "Treated"),
lty = 1,
col = c("blue", "orange")
)
adaptive_coding_samples = bcf_model.extract_parameter("adaptive_coding")
fig, ax = plt.subplots()
ax.plot(adaptive_coding_samples[0, :], color="blue", label="Control")
ax.plot(adaptive_coding_samples[1, :], color="orange", label="Treated")
ax.set_title("Adaptive Coding Parameter Traceplot")
ax.set_xlabel("Index")
ax.set_ylabel("Parameter Values")
ax.legend(loc="upper right")
plt.show()